Unified Multimodal Flow Matching with Cola DLM
Contents
Reading guide. The post starts with motivation and joint latent modeling, then moves into training design and qualitative results; for a quick pass, start with Sections 1, 3, and 4.
Abstract
Recent unified multimodal pretraining has moved beyond early single-stream autoregressive sequence modeling toward two-tower Reasoner–Generator paradigms, including cascaded MLLM-to-diffusion systems and parallel Mixture-of-Transformer (MoT) architectures. This post explores a different route built on Cola DLM (Continuous Latent Diffusion Language Model) [1]. We map both text and visual signals into continuous latent spaces and use a shared block-causal MMDiT to parameterize a latent generative distribution, so that understanding (text output) and generation (pixel output) can be trained through a unified interface. From this perspective, understanding and generation are different conditional views of the same multimodal joint distribution. Joint multitask pretraining constrains the shared generative distribution from multiple conditional directions, encouraging the model to learn semantic representations, cross-modal alignment, and generative dynamics in one representation space. We describe the architecture, its main design choices, and qualitative results on text-to-text, text-to-image, and image-and-text-to-text pretraining tasks.
1. Motivation: Why a Different Route to Unified Modeling?
In recent years, the central question in unified multimodal pretraining has shifted from whether a single system can support both understanding and generation to how the understanding and generation pathways should interact. At the architectural level, existing approaches can be broadly grouped into three lines of work.
Route 1: unified autoregressive sequence modeling. Chameleon [2] discretizes both text and images into tokens and predicts them with a single Transformer. Janus and Janus-Pro [3,4] further decouple the visual understanding encoder, such as SigLIP [5], from the discrete image tokenizer, such as VQ-VAE [6], while the generation path still largely relies on autoregressive modeling over discrete visual tokens. This route is closely aligned with the language-modeling paradigm and naturally supports interleaved inputs and outputs in a unified sequence format. Its limitation is that image generation quality and sampling efficiency are often constrained by discrete tokenization and long autoregressive sequences.
Route 2: parallel Reasoner–Generator interaction. Transfusion [7] jointly trains next-token prediction for text and diffusion objectives for images in a single multimodal model. BAGEL [8] adopts an MoT architecture in which understanding and generation experts operate over the same multimodal sequence and interact through shared self-attention. Show-o and Show-o2 [9,10] further study how to combine autoregressive text modeling and discrete diffusion-based visual generation inside a single Transformer. Tuna and Tuna-2 [11,12] start from unified visual representations and explore end-to-end unified modeling with continuous visual representations or pixel embeddings. These methods preserve autoregressive modeling on the text side while introducing diffusion objectives for the visual side, making them better suited to high-fidelity image generation than purely autoregressive systems. At the same time, they must handle more complex optimization coupling among representation learning, task mixture, and generation/understanding objectives.
Route 3: cascaded Reasoner-to-Generator bridging. MetaQueries [13] uses learnable queries to extract generation conditions from a pretrained MLLM and feeds them through a connector into an MMDiT. Qwen-Image [14] uses Qwen2.5-VL as the semantic conditioner and combines it with a VAE and an MMDiT for image generation and editing. UniWorld-V1 [15], OmniGen2 [16], and UniVideo [17] follow similar ideas, transferring the understanding capability of an MLLM into conditioning signals for an MMDiT and extending the framework to image editing, in-context generation, and video generation/editing. This route has strong engineering scalability because it can reuse existing MLLM and MMDiT backbones. However, understanding and generation are usually connected through hidden states, queries, connectors, or dual-stream conditioning. The unification is therefore more system-level composition than direct modeling of a multimodal joint distribution by a single model.
These lines of work suggest that “unification” should not simply mean sharing one Transformer, nor should it be reduced to attaching a diffusion generator after a language model. Even when visual generation happens in a VAE latent space, cross-modal learning in many existing systems remains closer to conditional modeling: one modality conditions another, rather than the model explicitly capturing a joint distribution over multimodal latents.
Motivated by this observation, we aim to construct a unified training paradigm distinct from both parallel two-tower interaction and cascaded bridging. Text and visual signals are mapped by VAEs into continuous latent spaces, and a single shared block-causal MMDiT [18,19] models
\[p_\psi\big(z_0^{\text{text}}, z_0^{\text{pixel}}\big).\]Under this view, understanding (text output) and generation (pixel output) correspond to different conditional views of the same multimodal joint distribution. Multitask training constrains $p_\psi(z_0^{\text{text}}, z_0^{\text{pixel}})$ from multiple conditional directions, encouraging the model to capture mutual information between $Z^{\text{text}}$ and $Z^{\text{pixel}}$ and to share semantic representation, cross-modal alignment, and generative dynamics under one interface.
Cola DLM provides a mature continuous-latent formulation for text generation. In this post, we show how the same formulation can be extended naturally to other modalities and used as the basis for this unified training paradigm.
A Brief Recap of Cola DLM
Cola DLM is a continuous latent-variable diffusion language model. Its key idea is to avoid denoising at the token level. Instead, it:
- learns a stable text-to-continuous-latent and continuous-latent-to-text mapping with a Text VAE;
- models a global semantic prior in continuous latent space with a block-causal DiT;
- generates text in a streaming manner through a conditional decoder.
Diffusion is used for latent prior transport:
\[z_1 \sim p_1,\qquad z_0 = \Phi^{\psi}_{0\leftarrow 1}(z_1),\qquad x \sim p_\theta(x \mid z_0).\]This decomposition explicitly separates global semantic organization in continuous latent space from local textual realization in the decoder. The same separation becomes crucial when extending the model to additional modalities.
2. A Joint Distribution over Continuous Latents
Unified modeling should not rely only on a shared backbone, nor should it force different modalities into exactly the same representation space. A more natural approach is to first map text and visual observations into continuous latent variables, and then let a shared block-causal MMDiT model the joint distribution over these latents. In this way, textual semantics, visual content, and their correspondence are all handled through the same interface.
Concretely, we follow the same probabilistic decomposition as Cola DLM. Let $x_{\text{text}}$ and $x_{\text{pixel}}$ denote text and visual observations. Their corresponding encoders produce continuous latents:
\[z_0^{\text{text}} \in \mathcal{Z}_{\text{text}},\quad z_0^{\text{text}} \sim q_{\phi_{\text{text}}}(z \mid x_{\text{text}}), \qquad z_0^{\text{pixel}} \in \mathcal{Z}_{\text{pixel}},\quad z_0^{\text{pixel}} \sim q_{\phi_{\text{pixel}}}(z \mid x_{\text{pixel}}).\]We then form a joint latent variable and model a unified generative process:
\[\bar{z}_0 = \big(z_0^{\text{text}},\, z_0^{\text{pixel}}\big), \qquad p(x_{\text{text}}, x_{\text{pixel}}, \bar{z}_0) = p_\theta\big(x_{\text{text}}, x_{\text{pixel}} \mid \bar{z}_0\big)\, p_\psi(\bar{z}_0).\]The modality-specific VAE encoders and decoders convert between observation spaces and latent spaces, while the shared block-causal MMDiT parameterizes $p_\psi(\bar z_0)$ over $\mathcal{Z}{\text{text}}\times\mathcal{Z}{\text{pixel}}$, learning the joint distribution of text and visual latents. Prior transport now acts on the multimodal latent variable $\bar{z}_0$: the shared block-causal MMDiT first generates the joint latent state, and the corresponding decoders then produce text or pixel outputs. Continuous latents provide a unified modeling interface; they do not require all modalities to share an identical representation.
From the joint-distribution perspective, the training objective can be written as
\[\mathbb{E}[\mathcal{L}_{\text{ELBO}}] := \mathbb{E}_q\big[\log p_\theta(x_{\text{text}}, x_{\text{pixel}} \mid \bar{z}_0)\big] - I\big((X_{\text{text}}, X_{\text{pixel}});\, \bar{Z}_0\big) - \mathrm{KL}\big(\bar{q}(\bar{z}_0)\,\|\,p_\psi(\bar{z}_0)\big).\]The three terms correspond to three basic questions: whether the decoders can reconstruct text and visual observations from the joint latent $\bar z_0$; how much information about the input is retained in the latent variable; and whether the aggregated posterior $\bar q(\bar z_0)$ produced by the encoders can be matched by the shared prior $p_\psi(\bar z_0)$.
In this framework, text latents and visual latents need not be forced into pointwise comparable representations. The model can learn different conditional generation directions within the same joint distribution, such as $p_\psi(z^{\text{pixel}}\mid z^{\text{text}})$ or $p_\psi(z^{\text{text}}\mid z^{\text{pixel}})$.
Thus, the latent variables carry compressed high-level semantics, while the decoders realize those semantics as concrete text or pixel outputs. The unification happens at the level of the joint distribution over continuous latents, not merely through the reuse of a cross-modal backbone.
3. Architecture and Training

The overall architecture is shown on the right of Figure 1. For text and images, it contains the following components:
- Text path. A Text VAE maps text into continuous latents, and the text sequence is partitioned into blocks.
- Image path. An Image VAE maps images into compact latents, with each image treated as a single block.
- Shared block-causal MMDiT. This module operates over both text blocks and image blocks, parameterizes the joint latent generative distribution, and supports both intra-modal processing and cross-modal interaction. In the current image model, the stack uses roughly one third dual-stream and two thirds single-stream DiT blocks.
A single model supports three tasks under the same framework:
- Text-to-text (T2T),
- Text-to-image (T2I),
- Image-and-text-to-text (IT2T), including captioning and visual question answering.
Sequence Layout
We pack continuous latents into a sequence and annotate each position with two integers. Suppose a packed sequence has $N$ positions. Position $i$ carries:
- a segment type $s_i \in {\textsf{P}, \textsf{C}, \textsf{I}, \textsf{N}}$, denoting instruction text, clean text, image, and noisy text, respectively;
- a block index $b_i \in \mathbb{Z}$, which partitions text into contiguous blocks of size $B$ (we use $B=16$ in the current implementation).
Text latents are split by block size $B$, while an image latent is treated as a single block. These two annotations carry all task semantics:
- Clean text ($\textsf{C}$) latents are context/conditioning and receive no loss.
- Noisy text ($\textsf{N}$) latents are generation targets and receive the diffusion loss.
- Instruction ($\textsf{P}$, used only for IT2T) latents are task prompts and also serve as context. They are separated from $\textsf{C}$ to avoid mixing the condition with the target, as explained in the IT2T section below.
- Block indices impose causal order across text blocks while keeping each block, and each single image block, bidirectional internally.
The task is defined only by (i) which segments are present and in what order, and (ii) the attention rule that couples them. The layouts are:
| Task | Per-sample segment layout | Diffusion target |
|---|---|---|
| Text-to-text (T2T) | $[\,\textsf{C}\,]\,[\,\textsf{N}\,]$ | text blocks |
| Text-to-image (T2I) | $[\,\textsf{C}\,]\,[\,\textsf{I}\,]\,[\,\textsf{N}\,]$ | image (primary) + caption (auxiliary) |
| Image-and-text-to-text (IT2T) | $[\,\textsf{P}\,]\,[\,\textsf{I}\,]\,[\,\textsf{C}\,]\,[\,\textsf{N}\,]$ | text only ($\textsf{P},\textsf{I}$ are fixed context) |
Within a single forward pass, multiple samples, possibly from different tasks under gradient accumulation, are concatenated into one long sequence. Attention is additionally constrained to stay within the same sample: query position $i$ may attend only to key position $j$ from the same sample.
Attention Masks as Task Semantics
The task semantics of the shared block-causal MMDiT are controlled by the attention mask $M_{ij}\in{0,1}$, which determines whether query $i$ may attend to key $j$. The mask is defined by the following segment-conditioned rules. Figure 2 visualizes small rendered examples for each task, with rows as queries and columns as attended keys.
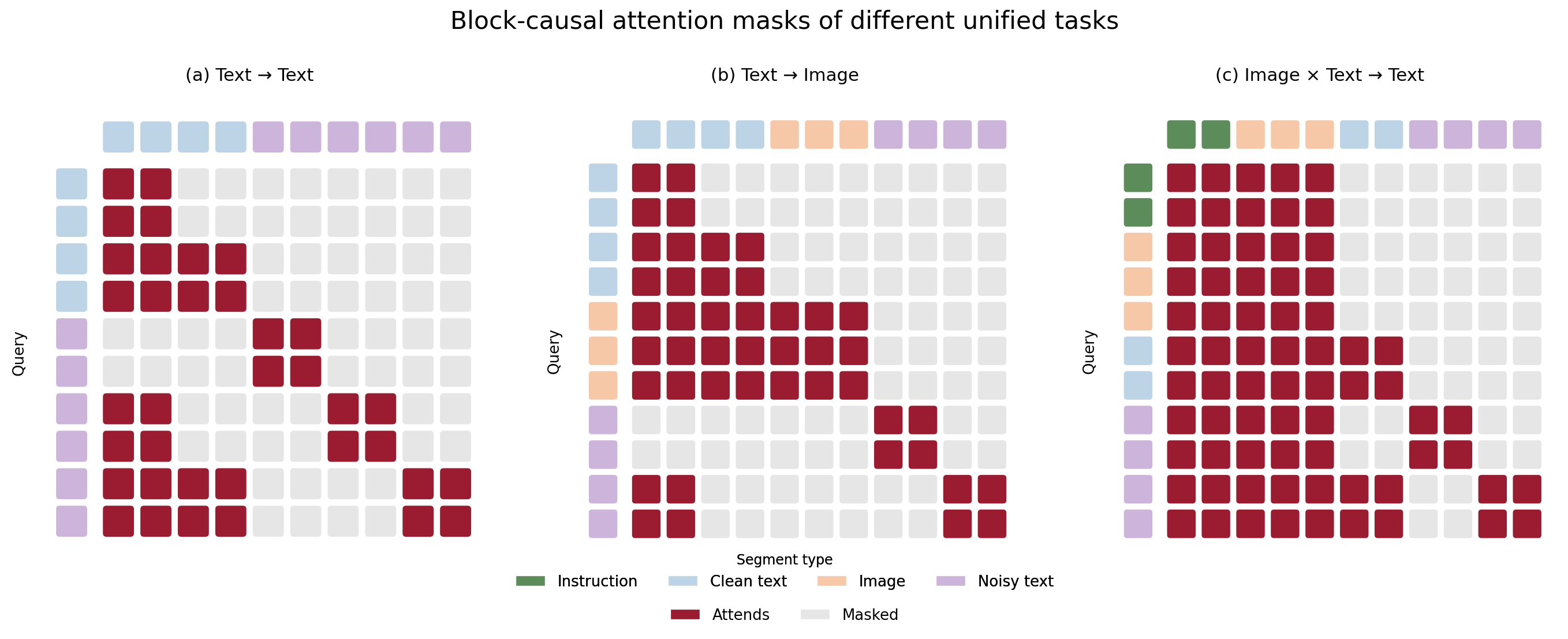
Text-to-image. Image generation is conditioned on clean text. We additionally append noisy text to enable multitask training inside a single sequence (T2I + T2T). The attention rule is:
\[M_{ij}=1 \iff \begin{cases} s_j=\textsf{C}\ \wedge\ b_j\le b_i, & s_i=\textsf{C}\quad(\text{block-causal caption}),\\[2pt] s_j\in\{\textsf{C},\textsf{I}\}, & s_i=\textsf{I}\quad(\text{full caption conditioning + bidirectional self-attention}),\\[2pt] (s_j=\textsf{C}\ \wedge\ b_j<b_i)\ \vee\ (s_j=\textsf{N}\ \wedge\ b_j=b_i), & s_i=\textsf{N}\quad(\text{block-diffusion text}). \end{cases}\]The image segment and noisy-text segment do not attend to each other. Therefore, the two objectives are not coupled through the auxiliary text loss directly. They are coupled through (i) the image attending to the clean text, so that the text condition receives gradients from the image loss, and (ii) the shared block-causal MMDiT parameters.
Image-and-text-to-text. Both the instruction $\textsf{P}$ and the image $\textsf{I}$ are clean conditions, and the model generates a textual answer conditioned on them. The key design issue is that the clean text stream in IT2T contains both the task prompt and a teacher-forcing copy of the answer. If they are merged into the same segment, the answer can leak into the image representation and then be read by the noisy text, short-circuiting the diffusion objective. If the image cannot see the prompt at all, the visual encoding becomes task-agnostic. We therefore put the instruction in a separate segment $\textsf{P}$ and keep it separate from the answer context $\textsf{C}$:
\[M_{ij}=1 \iff \begin{cases} s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{P}\quad(\text{instruction and image form a bidirectional condition}),\\[2pt] s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{I}\quad(\text{image sees the instruction, but not the answer}),\\[2pt] (s_j=\textsf{C}\ \wedge\ b_j\le b_i)\ \vee\ s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{C}\quad(\text{answer context conditioned on prompt and image}),\\[2pt] (s_j=\textsf{C}\ \wedge\ b_j<b_i)\ \vee\ (s_j=\textsf{N}\ \wedge\ b_j=b_i)\ \vee\ s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{N}\quad(\text{block-diffusion answer conditioned on prompt and image}). \end{cases}\]The instruction and image thus form a single fully bidirectional condition block, allowing the visual encoding to be prompt-aware. At the same time, neither attends to the answer ($\textsf{C}$ or $\textsf{N}$), preventing the answer from leaking backward into the condition. The answer part, consisting of the $\textsf{C}$ context and $\textsf{N}$ target, follows the block-causal structure and is conditioned on ${\textsf{P},\textsf{I}}$. Because the image is never used as an answer query target in this task, it serves only as context and the image diffusion loss is disabled.
Text-to-text is the special case of the T2I rule with the image segment removed: a clean prefix is encoded in a block-causal manner, and the remaining text blocks are generated by block diffusion conditioned on previous clean blocks.
Objective
The per-step loss is the sum of all active objectives:
\[\mathcal{L} = \mathcal{L}_{\text{image}} \;+\; \mathcal{L}_{\text{text}} \;+\; \mathcal{L}_{\text{REPA}},\]Each term is a velocity-prediction MSE in the corresponding latent space. $\mathcal{L}_{\text{REPA}}$ is an optional representation-alignment term [20], active only for T2I, that aligns intermediate DiT features with visual-encoder features to accelerate generation convergence. During training, tasks are sampled according to configurable task ratios, and the task choice is synchronized across workers to keep distributed collective calls consistent.
Training Setup
- Noise schedule. Both modalities use a rectified-flow linear interpolation schedule, velocity prediction, and an Euler sampler.
- Block-level noise. For text, each block samples its own timestep and all tokens within the block share that timestep, following the hierarchical block-causal design of Cola DLM. Image latents are noised as a single block.
- Modality-specific timestep sampling. Training timesteps are sampled independently for image and text blocks from logit-normal distributions.
- Classifier-free guidance. During training, the entire text condition of a T2I sample is randomly dropped so that the model learns an unconditional visual generation distribution.
All modules are pretrained from scratch, with task data ratios adjusted across pretraining stages. The results reported here correspond to a proof-of-concept pretraining scale, without large-scale instruction tuning or RL post-training:
| Task | Setup |
|---|---|
| Text-to-image | 256 resolution for 80k steps (global batch ≈ 3k), followed by 640 resolution for 10k steps (global batch ≈ 1k) |
| Image-and-text-to-text | same batch configuration, about 50k steps |
| Text data (total) | about 1B text tokens |
| Multimodal supervision | about 5M image-text pairs |
Under this limited data and compute budget, the model can already generate coherent text, produce reasonably structured images, and show preliminary image-captioning ability. This suggests that learning a joint distribution first in latent space and then delegating final realization to modality-specific decoders may be a data-efficient route to cross-modal capability.
4. Qualitative Results
This section reports qualitative results on the three tasks.
4.1 Text-to-image
Click any thumbnail to inspect the image in a larger viewer and continue browsing sample by sample.
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
4.2 Image-and-text-to-text
After training on about 5M image-text pairs, the model shows preliminary image-captioning ability and can generate text conditioned on image content.
 ›
›
Output: The image shows a woman wearing an oversized long down jacket with a plain collar. The jacket features a letter ``A'' design on it.
 ›
›
Output: The image shows a person wearing a black jacket and sunglasses, standing on a street.
 ›
›
Output: The image shows a meeting room with several people, around six to eight, sitting around a long conference table and holding a meeting. A screen is mounted on the wall, and bowls, cups, and pens are placed on the table.
 ›
›
Output: The image shows a person wearing a grey hoodie with a purple design on the front. The background includes a white wall with a blue design.
 ›
›
Output: The image shows several people playing a ball game on a court. The background includes a blue wall with some text, and the ground is also blue.
 ›
›
Output: The image shows a person wearing a black suit with a white shirt underneath, seated.
 ›
›
Output: The image shows a cluster of ancient buildings with old-style architecture, featuring several old structures packed closely together.
 ›
›
Output: The image is a cityscape shot at dusk, showing an urban night scene with many tall high-rise buildings.
 ›
›
Output: The image shows a large football (soccer) stadium with the field inside, resembling an outdoor stadium. Another row of stands is visible on the other side of the field.
 ›
›
Output: The image shows a person using a pen to write on a piece of paper.
 ›
›
Output: The image shows a woman with long, dark hair wearing a black top. The background is a neutral color, with a window and a pink wall visible behind her. She appears to be standing indoors.
 ›
›
Output: The image shows a portrait of a young woman with blonde hair, wearing a white top and seated at a student desk with an open laptop. She appears to be speaking while using the laptop.
 ›
›
Output: The image shows a gravestone with English text carved on it.
 ›
›
Output: The image shows a cluster of modern city buildings, including tall skyscrapers with distinctive and futuristic architectural designs.
 ›
›
Output: The image is a medium shot of a young East Asian woman with long, straight dark hair, wearing a pink top and a necklace. She is posing with her hands raised near her face, making a gesture with her fingers.
 ›
›
Output: The image shows a blue card or cover with a printed image and some text on it.
 ›
›
Output: The image shows three people standing in an open outdoor area. They are wearing colored clothing, and one of them appears to be carrying something on their back.
 ›
›
Output: The image shows a mountain range with a massive peak. The surface of the mountain reveals distinctive textures and patterns.
 ›
›
Output: The image shows a man wearing a plaid shirt, working in a studio or workshop. He is focused on an object on a white surface in front of him.
 ›
›
Output: The image shows a newlywed couple at a wedding, dressed in wedding attire.
 ›
›
Output: The image is a cartoon-style drawing of a character dressed in a colored outfit, with a body showing green and yellow stripes. The character is touching its face with one hand.
 ›
›
Output: The image shows musicians performing with instruments at a ceremony. The background includes a floor and a wall.
 ›
›
Output: The image shows a black sleeveless T-shirt with a printed design on the front.
 ›
›
Output: The image shows a person wearing a white blouse over a black and white striped skirt.
 ›
›
Output: The image shows a white Toyota car with a sleek design, featuring prominent front and side headlights.
 ›
›
Output: The image shows a man wearing a black baseball cap and a grey shirt. The focus is on the cap, and the background is a plain, neutral grey.
 ›
›
Output: The image shows a necklace with a red, ball-shaped pendant.
 ›
›
Output: The image shows a person standing on a paved area with a scenic green backdrop.
 ›
›
Output: The image shows an old building with distinctive traditional Chinese-style architecture. It features traditional entrance details, and an iron structure with a roof is visible above the building.
 ›
›
Output: The image shows a decorative ornament in the shape of a flower.
 ›
›
Output: The image shows several people playing volleyball, with one of them jumping up. The scene takes place under a clear afternoon sky.
 ›
›
Output: The image shows a soccer player in action during a match, wearing a numbered uniform. The player appears to be running and kicking the ball on the field.
 ›
›
Output: The image shows a black T-shirt with a design featuring a blue cat printed on the front.
 ›
›
Output: The image shows a young boy wearing a grey vest over a white shirt, with a blue accent.
 ›
›
Output: The image shows a young girl with straight hair, wearing a yellow crop top and white shorts. She is making a fist with one hand and jumping, set against a blue background.
 ›
›
Output: The image shows the stands of a large soccer stadium. The field and running track are visible, with green grass surrounding the stands and a few spectators present.
Note on images. The images used in the image-and-text-to-text examples are generated by external image-generation models from ground-truth captions, to avoid copyright issues associated with real photographs.
4.3 Text-to-text
Although trained with only about 1B text tokens, the unified model retains reasonably coherent text-continuation ability across conversational, narrative, expository, technical, and article-style prompts.
5. Future Experiments: From Feasibility to Quantitative Comparison
The current results primarily validate the feasibility of the proposed unified modeling scheme: a single model can acquire text generation, image generation, and preliminary image-text understanding ability under the same pretraining recipe. The next question is whether this unified model, after scaling pretraining and adding necessary SFT/RL post-training, can outperform standard alternatives. To answer this, we plan two controlled quantitative studies.
(Q1) Under controlled settings, does unified multimodal pretraining improve generation (pixel output)? We will first compare against a standard MMDiT baseline. This baseline follows the conventional text-to-image setup, where text is used only as a conditioning input and is not part of the joint latent-variable modeling. The comparison will match data, parameter count, and number of training samples, isolating the effect of the training paradigm itself and testing whether modeling a joint latent distribution with a shared MMDiT yields measurable gains in generation quality.
(Q2) Does unified multimodal pretraining also improve understanding (text output)? Beyond generation quality, we will evaluate whether shared-MMDiT modeling improves multimodal understanding and compare it systematically with other unified modeling paradigms.
Future work will also report scaling behavior, controlled matched comparisons, and results on standard generation and understanding benchmarks.
6. Roadmap: More Modalities under a Shared Joint Prior
The framework naturally extends to more modalities by introducing the corresponding block layouts and attention rules. Potential extensions include:
- Video. Temporally blocked latents fit the block-causal structure naturally: each frame or clip becomes a block, with causal structure across blocks and bidirectional modeling within each block. This form supports interleaved image, text, and video generation and understanding in a single sequence.
- Audio. Continuous audio latents can be introduced as another segment type, enabling text-audio and video-audio alignment for tasks such as captioning, narration, and sound-conditioned generation.
- Action. Continuous action latents, such as trajectories or control signals, can be incorporated into the shared block-causal MMDiT, supporting joint reasoning over perception and action and providing an interface for world-model-style learning.
References
[1] H. Guo, Q. Zhao, Y. Zhao, S. Nie, R. Zhu, Q. Guo, F. Wang, T. Yang, H. Zhao, G. Wei, and Y. Zeng, “Continuous Latent Diffusion Language Model,” arXiv:2605.06548, 2026. https://arxiv.org/abs/2605.06548
[2] Chameleon Team, “Chameleon: Mixed-Modal Early-Fusion Foundation Models,” arXiv:2405.09818, 2024. https://arxiv.org/abs/2405.09818
[3] C. Wu et al., “Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation,” arXiv:2410.13848, 2024. https://arxiv.org/abs/2410.13848
[4] X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling,” arXiv:2501.17811, 2025. https://arxiv.org/abs/2501.17811
[5] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid Loss for Language Image Pre-Training,” ICCV, 2023. https://arxiv.org/abs/2303.15343
[6] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural Discrete Representation Learning,” NeurIPS, 2017. https://arxiv.org/abs/1711.00937
[7] C. Zhou, L. Yu, A. Babu, K. Tirumala, M. Yasunaga, L. Shamis, J. Kahn, X. Ma, L. Zettlemoyer, and O. Levy, “Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model,” arXiv:2408.11039, 2024. https://arxiv.org/abs/2408.11039
[8] C. Deng et al., “Emerging Properties in Unified Multimodal Pretraining,” arXiv:2505.14683, 2025. https://arxiv.org/abs/2505.14683
[9] J. Xie et al., “Show-o: One Single Transformer to Unify Multimodal Understanding and Generation,” arXiv:2408.12528, 2024. https://arxiv.org/abs/2408.12528
[10] J. Xie, Z. Yang, and M. Z. Shou, “Show-o2: Improved Native Unified Multimodal Models,” arXiv:2506.15564, 2025. https://arxiv.org/abs/2506.15564
[11] Z. Liu et al., “Tuna: Taming Unified Visual Representations for Native Unified Multimodal Models,” arXiv:2512.02014, 2025. https://arxiv.org/abs/2512.02014
[12] Z. Liu et al., “Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation,” arXiv:2604.24763, 2026. https://arxiv.org/abs/2604.24763
[13] X. Pan et al., “Transfer between Modalities with MetaQueries,” arXiv:2504.06256, 2025. https://arxiv.org/abs/2504.06256
[14] C. Wu et al., “Qwen-Image Technical Report,” arXiv:2508.02324, 2025. https://arxiv.org/abs/2508.02324
[15] B. Lin et al., “UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation,” arXiv:2506.03147, 2025. https://arxiv.org/abs/2506.03147
[16] C. Wu et al., “OmniGen2: Towards Instruction-Aligned Multimodal Generation,” arXiv:2506.18871, 2025. https://arxiv.org/abs/2506.18871
[17] C. Wei et al., “UniVideo: Unified Understanding, Generation, and Editing for Videos,” arXiv:2510.08377, 2025. https://arxiv.org/abs/2510.08377
[18] W. Peebles and S. Xie, “Scalable Diffusion Models with Transformers,” arXiv:2212.09748, 2022. https://arxiv.org/abs/2212.09748
[19] P. Esser et al., “Scaling Rectified Flow Transformers for High-Resolution Image Synthesis,” ICML, 2024. https://arxiv.org/abs/2403.03206
[20] S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie, “Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think,” ICLR, 2025. https://arxiv.org/abs/2410.06940
Cola DLM project page: https://hongcanguo.github.io/Cola-DLM/