基于 Cola DLM 的统一多模态 Flow Matching
目录
阅读提示。 本文从动机与统一潜变量建模开始,随后介绍训练结构和定性结果;如果只想快速浏览,可优先阅读第 1、3、4 节。
摘要
最近,统一多模态预训练模型已从早期的单一自回归序列建模,发展为由 Reasoner Tower 与 Generator Tower 组成的双塔范式,包括 MLLM-to-Diffusion 的串联桥接结构,以及基于 Mixture-of-Transformer(MoT)的双塔并联结构。本文探索一种新的基于 Cola DLM(连续潜变量扩散语言模型)[1] 的统一建模方案:将文本与视觉信号映射到连续潜变量空间,并使用共享块因果 MMDiT 参数化潜变量生成分布,在统一接口下同时学习理解(text output)与生成(pixel output)。本方法将理解与生成视为同一多模态联合分布的不同条件视角,并通过多任务联合预训练在共享生成分布中同时学习语义表示、跨模态对齐与生成动力学,增强不同模态之间的互信息约束,从而为理解与生成任务提供一种协同机制。本文系统阐述该架构及其关键设计,并展示 文本→文本、文本→图像、图像×文本→文本 三类预训练任务的定性结果。
1. 动机:为什么需要新的统一建模路线?
近年来,统一多模态预训练建模的研究重点已从「能否用单一系统同时支持理解与生成」,转向「理解路径与生成路径应如何交互和协同」。从架构角度看,现有方法可概括为三类路线。
路线一:统一自回归序列建模。 Chameleon [2] 将文本与图像均离散化为 token,并在同一 Transformer 中进行预测;Janus / Janus-Pro [3,4] 进一步解耦视觉理解编码器(如 SigLIP [5])与离散图像 tokenizer(VQ-VAE [6]),但其生成路径仍主要依赖离散视觉 token 的自回归建模。该路线与语言模型范式最为一致,能够以统一序列形式支持交错形式的输入输出;其局限在于图像生成质量和采样效率通常受制于离散 tokenizer 与长序列自回归生成。
路线二:Reasoner–Generator 双塔并联交互。 Transfusion [7] 在同一多模态模型中联合训练文本 next-token prediction 与图像 diffusion 目标;BAGEL [8] 采用 MoT 架构,使理解专家与生成专家在同一多模态序列上工作,并通过共享 self-attention 实现长上下文交互。Show-o / Show-o2 [9,10] 进一步探索在单一 Transformer 中结合自回归文本建模与离散 diffusion 视觉生成;Tuna / Tuna-2 [11,12] 则从统一视觉表示出发,分别探索连续视觉表示与 pixel embedding 的端到端统一建模。此类方法保留文本侧的 AR 建模,同时在视觉侧引入 diffusion head,相比纯 AR 架构更适合高保真视觉生成;相应地,它需要在表征学习、任务配比以及生成/理解目标之间处理更复杂的优化耦合。
路线三:Reasoner-to-Generator 串联桥接。 MetaQueries [13] 使用可学习 query 从预训练 MLLM 中提取生成条件,并经由 connector 输入 MMDiT;Qwen-Image [14] 使用 Qwen2.5-VL 提供语义条件,并结合 VAE 与 MMDiT 完成图像生成与编辑;UniWorld-V1 [15]、OmniGen2 [16] 和 UniVideo [17] 同样采用类似的思路,将 MLLM 的理解能力转化为 MMDiT 的条件信号,并扩展至图像编辑、in-context 生成以及视频生成与编辑。该路线具有较强工程可扩展性,能够充分复用已有 MLLM 与 MMDiT 基座。理解与生成通常通过 hidden states、query、connector 或双流条件进行连接,其统一性更多体现为系统级组合,而非由单一模型直接建模多模态联合分布。
上述研究表明,「统一」既不能简单等同于共享一个 Transformer,也不能仅理解为在语言模型之后接入扩散生成模块。即使视觉生成已经发生在 VAE latent 上,大多数现有方法中的跨模态学习仍更接近条件建模,即以一种模态作为另一种模态的条件,而非显式刻画多模态潜变量的联合分布。 基于上述观察,本文旨在构建一种区别于双塔并联或串联桥接的统一训练范式:文本与视觉信号经由 VAE 映射到连续 latent space,并由单一共享的块因果 MMDiT [18,19] 建模
\[p_\psi\big(z_0^{\text{text}}, z_0^{\text{pixel}}\big).\]在该视角下,理解(text output)和生成(pixel output)对应同一多模态联合分布的不同条件视角。多任务联合训练从多个条件方向约束 $p_\psi(z_0^{\text{text}}, z_0^{\text{pixel}})$,促使模型捕获 $Z^{\text{text}}$ 与 $Z^{\text{pixel}}$ 之间的互信息,并在统一接口下共享语义表示、跨模态对齐与生成动力学。 Cola DLM 为文本生成提供了完善的连续潜变量建模方案。本文进一步说明,该方案可自然扩展至其他模态,并为上述统一训练范式提供基础。
Cola DLM 回顾
Cola DLM 是一种连续潜变量扩散语言模型。其核心是不在 token 层面执行去噪,而是:
- 用 Text VAE 学习稳定的 文本 ↔ 连续潜变量 映射;
- 用 块因果 DiT 在连续潜空间建模全局语义先验;
- 通过条件解码器流式生成文本。
扩散过程用于潜变量先验传输:
\[z_1 \sim p_1,\qquad z_0 = \Phi^{\psi}_{0\leftarrow 1}(z_1),\qquad x \sim p_\theta(x \mid z_0).\]该分解显式区分了全局语义组织(连续潜空间)与局部文本实现(解码器)。在扩展至其他模态时,这种分工同样关键。
2. 连续潜变量上的联合分布
统一建模不应只依赖共享骨干网络,也不应把不同模态强行压到同一表征空间。更自然的做法是先把文本和视觉信号分别映射到连续潜变量,再让共享块因果 MMDiT 建模这些潜变量的联合分布。这样,文本语义、视觉内容以及二者之间的对应关系都可以通过同一个接口来处理。
具体而言,本文遵循与 Cola DLM 相同的概率分解。设 $x_{\text{text}}$、$x_{\text{pixel}}$ 为文本与视觉观测,由相应编码器产生连续潜变量:
\[z_0^{\text{text}} \in \mathcal{Z}_{\text{text}},\quad z_0^{\text{text}} \sim q_{\phi_{\text{text}}}(z \mid x_{\text{text}}), \qquad z_0^{\text{pixel}} \in \mathcal{Z}_{\text{pixel}},\quad z_0^{\text{pixel}} \sim q_{\phi_{\text{pixel}}}(z \mid x_{\text{pixel}}).\]进一步,将文本与视觉 latent 构成联合潜变量并建模统一生成过程:
\[\bar{z}_0 = \big(z_0^{\text{text}},\, z_0^{\text{pixel}}\big), \qquad p(x_{\text{text}}, x_{\text{pixel}}, \bar{z}_0) = p_\theta\big(x_{\text{text}}, x_{\text{pixel}} \mid \bar{z}_0\big)\, p_\psi(\bar{z}_0).\]模态对应的 VAE 编解码器负责在观测空间和潜变量空间之间转换,共享块因果 MMDiT 则在 $\mathcal{Z}{\text{text}}\times\mathcal{Z}{\text{pixel}}$ 上参数化 $p_\psi(\bar z_0)$,学习文本 latent 与视觉 latent 的联合分布。「先验传输」可作用于多模态潜变量 $\bar{z}_0$:共享块因果 MMDiT 先生成联合潜变量,随后由对应解码器生成文本或 pixel 输出。连续潜变量的作用在于提供统一的建模接口,而不是要求所有模态共享同一种表示。
从联合分布的角度看,训练目标可以写成:
\[\mathbb{E}[\mathcal{L}_{\text{ELBO}}] = \mathbb{E}_q\big[\log p_\theta(x_{\text{text}}, x_{\text{pixel}} \mid \bar{z}_0)\big] - I\big((X_{\text{text}}, X_{\text{pixel}});\, \bar{Z}_0\big) - \mathrm{KL}\big(\bar{q}(\bar{z}_0)\,\|\,p_\psi(\bar{z}_0)\big).\]这三个项分别对应三个简单的问题:解码器能否从联合潜变量 $\bar z_0$ 还原文本和视觉观测;潜变量中保留了多少关于输入样本的信息;编码器得到的聚合后验 $\bar q(\bar z_0)$ 是否能被共享先验 $p_\psi(\bar z_0)$ 拟合。 在这个框架下,文本 latent 和视觉 latent 不需要被强行对齐成逐点可比的同一种表示。模型能够在同一个联合分布中学习不同的条件生成方向,例如 $p_\psi(z^{\text{pixel}}\mid z^{\text{text}})$,或 $p_\psi(z^{\text{text}}\mid z^{\text{pixel}})$。
因此,潜变量承载压缩后的高层语义,解码器负责把这些语义落实为具体的文本或 pixel 输出。统一建模发生在连续潜变量的联合分布上,而不只是复用同一个跨模态骨干网络。
3. 架构与训练

整体架构如图 1 右侧所示,以文本和图像两种模态为例,包含以下组成部分:
- 文本路径。 Text VAE 将文本映射为连续潜变量;文本序列被划分为块。
- 图像路径。 Image VAE 将图像映射为紧凑潜变量;每个图像被视为单一块。
- 共享块因果 MMDiT。 该模块在文本块与图像块上运算,用于参数化联合潜变量生成分布,并支持模态内处理与跨模态交互。当前图像实例中堆叠约 1/3 双流、2/3 单流 DiT 块。
单一模型在同一框架内支持三类任务:
- 文本 → 文本(T2T),
- 文本 → 图像(T2I),
- 图像 × 文本 → 文本(IT2T)(图像描述 / 视觉问答)。
序列排列
具体来说,我们将连续潜变量打包为序列,并为每个位置标注两个整数。设打包序列有 $N$ 个位置,位置 $i$ 携带:
- 段类型 $s_i \in {\textsf{P}, \textsf{C}, \textsf{I}, \textsf{N}}$,分别表示指令文本、无噪文本、图像、带噪文本;
- 块索引 $b_i \in \mathbb{Z}$,将文本划分为大小为 $B$ 的连续块(当前实现中 $B=16$)。
文本潜变量按块大小 $B$ 切分;图像潜变量视为单个块。两种标注承载全部任务语义:
- 无噪文本($\textsf{C}$)潜变量为上下文/条件,不计损失;
- 带噪($\textsf{N}$)潜变量为生成目标,接受扩散损失;
- 指令($\textsf{P}$,仅用于 IT2T 任务)为任务提示,同样作为上下文;其与 $\textsf{C}$ 分离,以避免条件与目标混淆(原因见下文 IT2T 部分);
- 块索引在文本块间施加因果顺序,同时使每个块内部以及单个图像内部保持双向注意力。
任务仅由 (i) 各段是否存在及顺序,(ii) 耦合它们的注意力规则定义,三种任务的布局如下:
| 任务 | 每样本段布局 | 扩散目标 |
|---|---|---|
| 文本 → 文本 (T2T) | $[\,\textsf{C}\,]\,[\,\textsf{N}\,]$ | 文本块 |
| 文本 → 图像 (T2I) | $[\,\textsf{C}\,]\,[\,\textsf{I}\,]\,[\,\textsf{N}\,]$ | 图像(主)+ 描述(辅) |
| 图像 × 文本 → 文本 (IT2T) | $[\,\textsf{P}\,]\,[\,\textsf{I}\,]\,[\,\textsf{C}\,]\,[\,\textsf{N}\,]$ | 仅文本($\textsf{P},\textsf{I}$ 为固定上下文) |
单次前向中,多个样本(梯度累积下可为不同任务)拼接为长序列;注意力额外约束在同一样本内部,即位置 $i$ 的 query 仅可 attend 到同一样本的位置 $j$。
注意力掩码作为任务语义的代理
共享块因果 MMDiT 的任务语义由注意力掩码 $M_{ij}\in{0,1}$ 控制,其决定 query $i$ 是否 attend 到 key $j$。掩码由以下段条件规则给出。图 2 为各任务小规模示例渲染得到的掩码(行为 query,列为被 attend 的 key)。
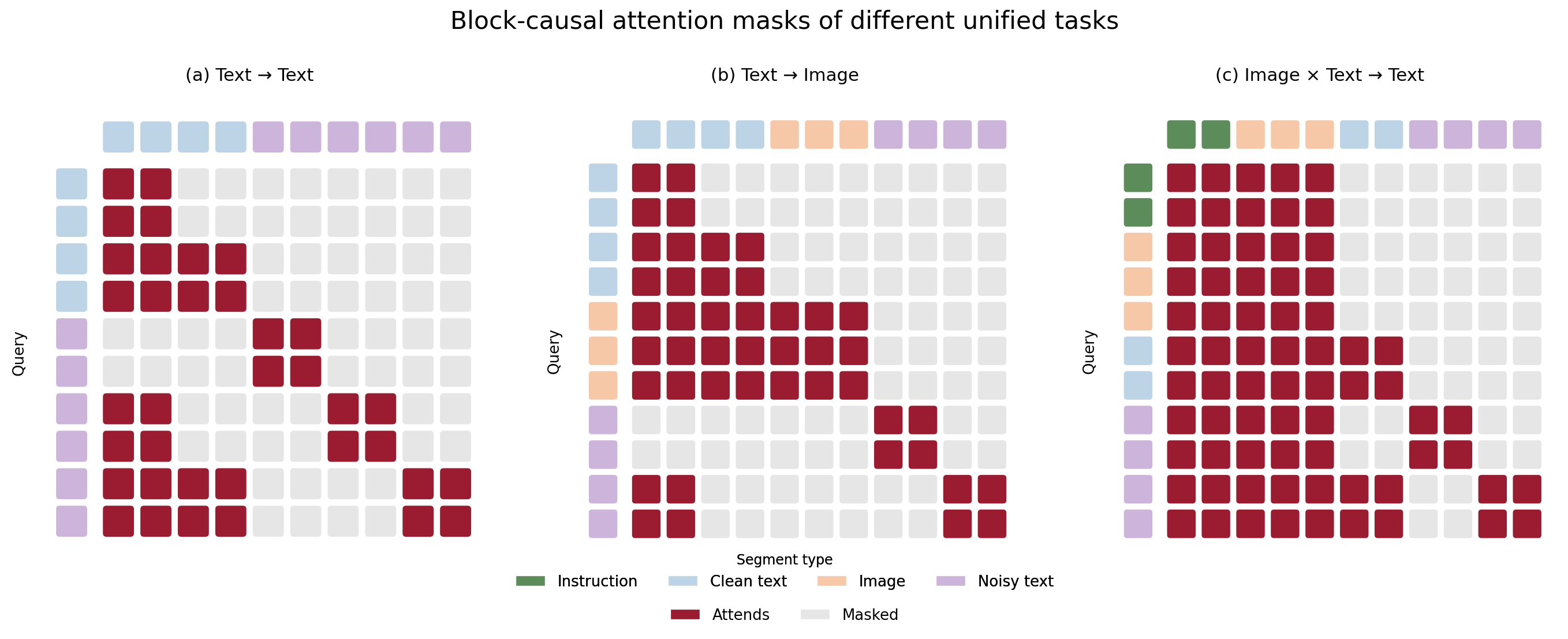
文本 → 图像。 图像生成以干净文本为条件。另外,额外拼接带噪文本做单一序列内部的多任务联训(T2I+T2T),注意力规则如下:
\[M_{ij}=1 \iff \begin{cases} s_j=\textsf{C}\ \wedge\ b_j\le b_i, & s_i=\textsf{C}\quad(\text{块因果描述}),\\[2pt] s_j\in\{\textsf{C},\textsf{I}\}, & s_i=\textsf{I}\quad(\text{完整描述条件 + 双向自注意力}),\\[2pt] (s_j=\textsf{C}\ \wedge\ b_j<b_i)\ \vee\ (s_j=\textsf{N}\ \wedge\ b_j=b_i), & s_i=\textsf{N}\quad(\text{块扩散文本}). \end{cases}\]需要指出,图像段与带噪文本段互不 attend。因此,两项目标并非通过辅助文本损失直接耦合,而是经由 (i) 图像 attend 干净文本,使文本条件从图像损失获得梯度,以及 (ii) 共享块因果 MMDiT 参数。
图像 × 文本 → 文本。指令 $\textsf{P}$ 与 图像 $\textsf{I}$ 均为干净条件,模型基于该条件生成文本答案。该任务的关键设计在于,IT2T 中的干净文本流同时包含任务提示与答案的 teacher-forcing 副本。若将二者合并为同一段,会导致答案泄漏到图像表示中并被带噪文本读取,从而短路扩散目标;若图像完全不可见提示,则视觉编码又无法感知任务指令。因此,我们将指令置于独立段 $\textsf{P}$,并与描述上下文 $\textsf{C}$ 分离,以解决该问题:
\[M_{ij}=1 \iff \begin{cases} s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{P}\quad(\text{指令与图像构成双向条件}),\\[2pt] s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{I}\quad(\text{图像见指令,不见答案}),\\[2pt] (s_j=\textsf{C}\ \wedge\ b_j\le b_i)\ \vee\ s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{C}\quad(\text{答案上下文,以提示与图像为条件}),\\[2pt] (s_j=\textsf{C}\ \wedge\ b_j<b_i)\ \vee\ (s_j=\textsf{N}\ \wedge\ b_j=b_i)\ \vee\ s_j\in\{\textsf{P},\textsf{I}\}, & s_i=\textsf{N}\quad(\text{块扩散答案,以提示与图像为条件}). \end{cases}\]由此,指令与图像形成单一、全双向的条件块,使视觉编码具备提示感知能力;同时二者均不 attend 答案($\textsf{C}$ 或 $\textsf{N}$),从而避免答案反向泄漏进条件。答案部分($\textsf{C}$ 上下文与 $\textsf{N}$ 目标)采用块因果结构,并以 ${\textsf{P},\textsf{I}}$ 为条件。由于图像从不作为答案 query 目标,在该任务中图像仅作为上下文,图像扩散损失被关闭。
文本 → 文本 可视为去除图像段后的 T2I 规则特例:无噪前缀通过块因果方式编码,其余文本块在先前无噪块条件下由块扩散生成。
目标函数
每步损失为各有效目标之和:
\[\mathcal{L} = \mathcal{L}_{\text{image}} \;+\; \mathcal{L}_{\text{text}} \;+\; \mathcal{L}_{\text{REPA}},\]各项均为相应潜空间中的速度预测 MSE。$\mathcal{L}_{\text{REPA}}$ 为可选表示对齐项[20](仅在 T2I 中激活),用于将 DiT 中间层与视觉编码器特征对齐以加速生成收敛。训练时按可配置任务比例在每个训练步采样任务,并在所有 worker 上同步任务选择,以保证分布式 collective 调用一致。
训练设置
- 噪声调度。 两模态均采用 rectified-flow 的线性插值方式,速度预测与 Euler 采样器。
- 块级噪声。 文本上每块独立采样一个时间步,块内所有 token 共享——继承自 Cola DLM 的层次化块因果核心。图像潜变量作为单块加噪。
- 模态专属时间步采样。 训练时间步按模态从 logit-normal 分布采样:图像块和文本块独立采样。
- Classifier-free guidance。 训练时随机丢弃 T2I 样本的整段文本条件,使模型学习无条件视觉生成分布。
所有模块均从零预训练,在不同预训练阶段调整任务数据比例。本文报告的是当前 Proof of Concept 规模的预训练设置,未经过大规模指令微调或 RL 后训练的完整系统:
| 任务 | 设置 |
|---|---|
| 文本 → 图像 | 256 分辨率 80k 步(全局 batch ≈ 3k),再 640 分辨率 10k 步(全局 batch ≈ 1k) |
| 图像 × 文本 → 文本 | 相同 batch 配置,约 50k 步 |
| 文本(合计) | 约 10 亿 文本 token |
| 多模态监督 | 约 500 万 图文对 |
在上述有限数据与算力设置下,模型已能够生成连贯文本、结构合理的图像,并表现出初步图像描述能力。这一结果表明,先在潜变量层面学习联合分布,再交由各模态解码器生成最终输出,可能是以较高数据效率获得跨模态能力的一种有效途径。
4. 定性结果
本节报告我们的模型在三类任务上的定性结果。
4.1 文本 → 图像
下面展示若干单图样本,点击任意缩略图可查看大图,并可继续逐张浏览。
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
 ›
›
4.2 图像 × 文本 → 文本
在训练约 500 万 图文对后,模型表现出初步的图像描述能力,能够根据图像内容生成相应文本。
 ›
›
Output: The image shows a woman wearing an oversized long down jacket with a plain collar. The jacket features a letter ``A'' design on it.
 ›
›
Output: The image shows a person wearing a black jacket and sunglasses, standing on a street.
 ›
›
Output: The image shows a meeting room with several people, around six to eight, sitting around a long conference table and holding a meeting. A screen is mounted on the wall, and bowls, cups, and pens are placed on the table.
 ›
›
Output: The image shows a person wearing a grey hoodie with a purple design on the front. The background includes a white wall with a blue design.
 ›
›
Output: The image shows several people playing a ball game on a court. The background includes a blue wall with some text, and the ground is also blue.
 ›
›
Output: The image shows a person wearing a black suit with a white shirt underneath, seated.
 ›
›
Output: The image shows a cluster of ancient buildings with old-style architecture, featuring several old structures packed closely together.
 ›
›
Output: The image is a cityscape shot at dusk, showing an urban night scene with many tall high-rise buildings.
 ›
›
Output: The image shows a large football (soccer) stadium with the field inside, resembling an outdoor stadium. Another row of stands is visible on the other side of the field.
 ›
›
Output: The image shows a person using a pen to write on a piece of paper.
 ›
›
Output: The image shows a woman with long, dark hair wearing a black top. The background is a neutral color, with a window and a pink wall visible behind her. She appears to be standing indoors.
 ›
›
Output: The image shows a portrait of a young woman with blonde hair, wearing a white top and seated at a student desk with an open laptop. She appears to be speaking while using the laptop.
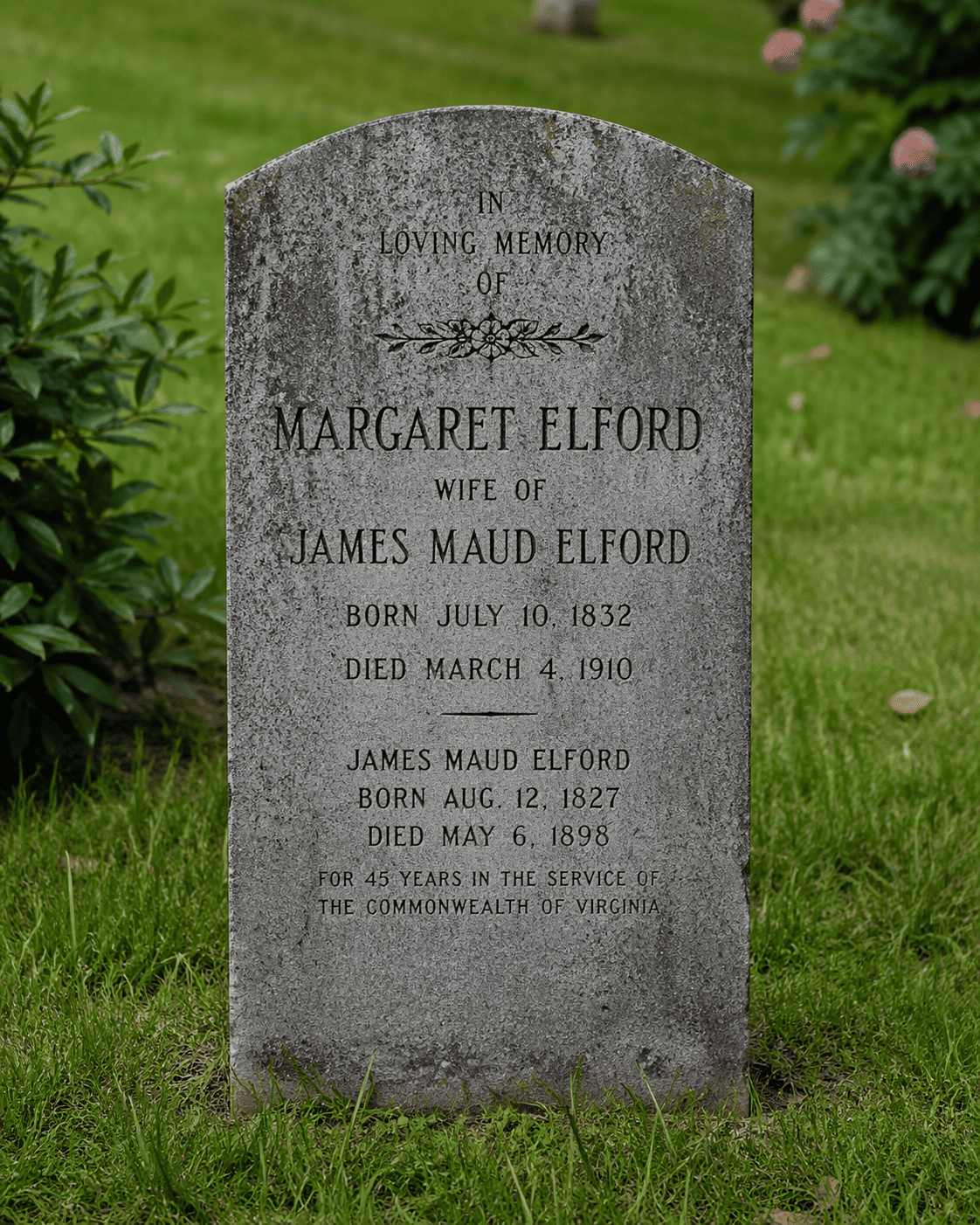 ›
›
Output: The image shows a gravestone with English text carved on it.
 ›
›
Output: The image shows a cluster of modern city buildings, including tall skyscrapers with distinctive and futuristic architectural designs.
 ›
›
Output: The image is a medium shot of a young East Asian woman with long, straight dark hair, wearing a pink top and a necklace. She is posing with her hands raised near her face, making a gesture with her fingers.
 ›
›
Output: The image shows a blue card or cover with a printed image and some text on it.
 ›
›
Output: The image shows three people standing in an open outdoor area. They are wearing colored clothing, and one of them appears to be carrying something on their back.
 ›
›
Output: The image shows a mountain range with a massive peak. The surface of the mountain reveals distinctive textures and patterns.
 ›
›
Output: The image shows a man wearing a plaid shirt, working in a studio or workshop. He is focused on an object on a white surface in front of him.
 ›
›
Output: The image shows a newlywed couple at a wedding, dressed in wedding attire.
 ›
›
Output: The image is a cartoon-style drawing of a character dressed in a colored outfit, with a body showing green and yellow stripes. The character is touching its face with one hand.
 ›
›
Output: The image shows musicians performing with instruments at a ceremony. The background includes a floor and a wall.
 ›
›
Output: The image shows a black sleeveless T-shirt with a printed design on the front.
 ›
›
Output: The image shows a person wearing a white blouse over a black and white striped skirt.
 ›
›
Output: The image shows a white Toyota car with a sleek design, featuring prominent front and side headlights.
 ›
›
Output: The image shows a man wearing a black baseball cap and a grey shirt. The focus is on the cap, and the background is a plain, neutral grey.
 ›
›
Output: The image shows a necklace with a red, ball-shaped pendant.
 ›
›
Output: The image shows a person standing on a paved area with a scenic green backdrop.
 ›
›
Output: The image shows an old building with distinctive traditional Chinese-style architecture. It features traditional entrance details, and an iron structure with a roof is visible above the building.
 ›
›
Output: The image shows a decorative ornament in the shape of a flower.
 ›
›
Output: The image shows several people playing volleyball, with one of them jumping up. The scene takes place under a clear afternoon sky.
 ›
›
Output: The image shows a soccer player in action during a match, wearing a numbered uniform. The player appears to be running and kicking the ball on the field.
 ›
›
Output: The image shows a black T-shirt with a design featuring a blue cat printed on the front.
 ›
›
Output: The image shows a young boy wearing a grey vest over a white shirt, with a blue accent.
 ›
›
Output: The image shows a young girl with straight hair, wearing a yellow crop top and white shorts. She is making a fist with one hand and jumping, set against a blue background.
 ›
›
Output: The image shows the stands of a large soccer stadium. The field and running track are visible, with green grass surrounding the stands and a few spectators present.
关于图像说明。 图像×文本→文本示例中的图像由外部图像生成模型根据真值描述生成,以避免真实照片相关的版权问题。
4.3 文本 → 文本
尽管仅使用约 10 亿 文本 token 进行训练,统一模型在对话、叙事、说明、技术与文章式提示下仍能保持较为连贯的文本续写能力。
5. 后续实验:从可行性到定量对比
本文当前结果主要验证了该统一建模方案的可行性:单一模型可在同一预训练配方下同时获得文本生成、图像生成与初步图文理解能力。后续工作需要进一步回答该统一模型在放大预训练规模并引入必要的 SFT/RL 后训练后,是否优于标准替代方案。为此,后续我们将开展以下两类定量对照实验。
(Q1) 在受控设置下,统一多模态预训练是否改善生成(pixel output)? 首先,本文将与 标准 MMDiT 基线进行直接比较。该基线采用常规文本→图像设置,其中文本仅作为条件输入,而不参与联合潜变量建模。比较将在数据、参数量与训练样本数匹配的条件下进行,以隔离训练范式本身的影响,并检验共享 MMDiT 建模联合潜变量分布是否能带来可测的生成质量增益。
(Q2) 统一多模态预训练是否也改善理解(text output)? 其次,除生成质量外,后续还将评估共享 MMDiT 建模是否能改善多模态理解能力,并与其他统一建模范式进行系统比较。
此外,后续研究将报告 scaling 行为、受控匹配对照以及标准生成与理解基准结果。
6. 路线图:共享联合先验下的更多模态
本框架可以自然扩展至更多模态,并配以相应的块布局与注意力规则。可扩展的模态包括:
- 视频。 时间分块的潜变量可自然适配块因果结构:每帧或片段构成一个块,块间采用时间因果结构,块内采用双向建模。这一形式支持在单一序列内进行图像、文本与视频的交错生成和理解。
- 音频。 连续音频潜变量可作为另一类段类型,用于建模文本↔音频、视频↔音频之间的对齐关系,例如描述、旁白和声音条件生成。
- 动作。 连续动作潜变量(轨迹、控制信号)可被纳入共享块因果 MMDiT 中,从而支持感知与动作的联合推理,并为世界模型式建模提供接口。
References
[1] H. Guo, Q. Zhao, Y. Zhao, S. Nie, R. Zhu, Q. Guo, F. Wang, T. Yang, H. Zhao, G. Wei, and Y. Zeng, “Continuous Latent Diffusion Language Model,” arXiv:2605.06548, 2026. https://arxiv.org/abs/2605.06548
[2] Chameleon Team, “Chameleon: Mixed-Modal Early-Fusion Foundation Models,” arXiv:2405.09818, 2024. https://arxiv.org/abs/2405.09818
[3] C. Wu et al., “Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation,” arXiv:2410.13848, 2024. https://arxiv.org/abs/2410.13848
[4] X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling,” arXiv:2501.17811, 2025. https://arxiv.org/abs/2501.17811
[5] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid Loss for Language Image Pre-Training,” ICCV, 2023. https://arxiv.org/abs/2303.15343
[6] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural Discrete Representation Learning,” NeurIPS, 2017. https://arxiv.org/abs/1711.00937
[7] C. Zhou, L. Yu, A. Babu, K. Tirumala, M. Yasunaga, L. Shamis, J. Kahn, X. Ma, L. Zettlemoyer, and O. Levy, “Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model,” arXiv:2408.11039, 2024. https://arxiv.org/abs/2408.11039
[8] C. Deng et al., “Emerging Properties in Unified Multimodal Pretraining,” arXiv:2505.14683, 2025. https://arxiv.org/abs/2505.14683
[9] J. Xie et al., “Show-o: One Single Transformer to Unify Multimodal Understanding and Generation,” arXiv:2408.12528, 2024. https://arxiv.org/abs/2408.12528
[10] J. Xie, Z. Yang, and M. Z. Shou, “Show-o2: Improved Native Unified Multimodal Models,” arXiv:2506.15564, 2025. https://arxiv.org/abs/2506.15564
[11] Z. Liu et al., “Tuna: Taming Unified Visual Representations for Native Unified Multimodal Models,” arXiv:2512.02014, 2025. https://arxiv.org/abs/2512.02014
[12] Z. Liu et al., “Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation,” arXiv:2604.24763, 2026. https://arxiv.org/abs/2604.24763
[13] X. Pan et al., “Transfer between Modalities with MetaQueries,” arXiv:2504.06256, 2025. https://arxiv.org/abs/2504.06256
[14] C. Wu et al., “Qwen-Image Technical Report,” arXiv:2508.02324, 2025. https://arxiv.org/abs/2508.02324
[15] B. Lin et al., “UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation,” arXiv:2506.03147, 2025. https://arxiv.org/abs/2506.03147
[16] C. Wu et al., “OmniGen2: Towards Instruction-Aligned Multimodal Generation,” arXiv:2506.18871, 2025. https://arxiv.org/abs/2506.18871
[17] C. Wei et al., “UniVideo: Unified Understanding, Generation, and Editing for Videos,” arXiv:2510.08377, 2025. https://arxiv.org/abs/2510.08377
[18] W. Peebles and S. Xie, “Scalable Diffusion Models with Transformers,” arXiv:2212.09748, 2022. https://arxiv.org/abs/2212.09748
[19] P. Esser et al., “Scaling Rectified Flow Transformers for High-Resolution Image Synthesis,” ICML, 2024. https://arxiv.org/abs/2403.03206
[20] S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie, “Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think,” ICLR, 2025. https://arxiv.org/abs/2410.06940
Cola DLM 项目页:https://hongcanguo.github.io/Cola-DLM/