Zhao Yian's Blog
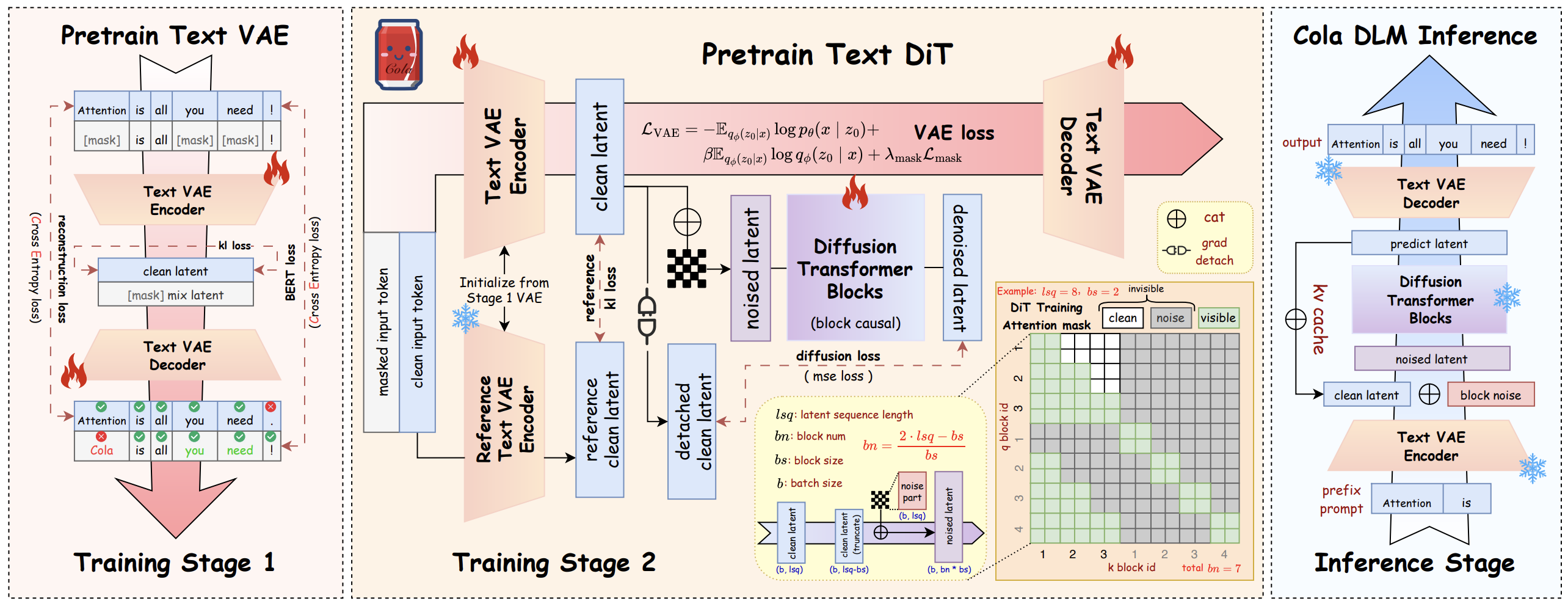
基于 Cola DLM 的统一多模态 Flow Matching
An exploration of unified text-vision modeling with Cola DLM, using continuous latent spaces and a shared block-causal MMDiT for understanding and generation.
An exploration of unified text-vision modeling with Cola DLM, using continuous latent spaces and a shared block-causal MMDiT for understanding and generation.